零基础小白如何入门人工智能?
来源:原创 时间:2017-11-28 浏览:0 次11月15日,国家宣告一个大音讯。科技部召开了新一代人工智能开展规划暨严重科技项目发动会,宣告第一批国家新一代人工智能敞开立异渠道名单:百度、阿里云、腾讯、科大讯飞。
这四家企业经过人工智能分别在无人车、公共体系、医学影像和语音辨认范畴上取得了行之有效的开展。
越来越多的人开端重视人工智能,学习人工智能。与此同时也有越来越多的人发生疑问:
究竟什么是人工智能?
人工智能能够处理什么问题?
零根底是否能够入门人工智能?
我们常常听到机器学习和深度学习,这二者有什么不同?
它们和人工智能又有什么联系呢?
下面我给我们共享一篇课程中关于机器学习的内容,如果你喜爱,能够购买我的达人课,了解更多内容。也欢迎我们与我沟通!
一、机器学习的布景
我们都说人工智能是归纳的学科,而机器学习就是人工智能的大脑。它经过对数据的处理,不断地变得更好和更强,做出各式各样的判别和决议计划。
人工智能从 1956 年提出概念以来履历了绵长的开展进程,中心有两次顶峰,两次低谷,现在是第三次顶峰,而带来开展崎岖的是机器学习算法的变迁。
第三次顶峰开端的标志是 2006 年的时分,机器学习算法中的神经网络方向呈现了一个打破,多伦多大学教授 Geoffrey Hinton 提出了“深度学习”的概念。
在接下来的几年中,由于核算机功能的提高和数据量的急速添加,深度学习技能的实用性越来越强。

人工智能开展途径
有人说,已然前两次顶峰都失利了,这第三次顶峰是不是也仅仅“狼来了”呢?
老套的台词:“这一次不一样”。
其实我们所做的一切 AI,都是有等待的,我们等待的是什么呢?等待它能代替人。
机器代替人的重要规范是什么?就是比人更好。很惋惜,前两次的浪潮,核算机仅仅证明它比人算的快,它没有证明它比人算的准。
但这一次,深度学习改动了这一切,人工智能全面逾越人类。
拿简历分类来说,一般 HR 人工分类的精确程度大概是 85%,之前用 SVM( Support Vector Machine,支撑向量机) 做精确率是 60% 多,仍是不如人的。而现在用深度学习算法,精确率能够超越 90%,比人要精确的多,而且速度是人的 N 倍。
观看一下身边的改动:当我们翻开支付宝时,机器学习会给我们做面部辨认;
当我们阅读电商网站时,机器学习算法猜测我们对哪种产品更感兴趣,然后显现给我们;
当我们翻开今天头条时,机器学习算法根据我们的阅读习气给我们引荐可能感兴趣的新闻。能够说,机器学习早已进入我们日子的方方面面。
所以,这次“狼”真的来了。
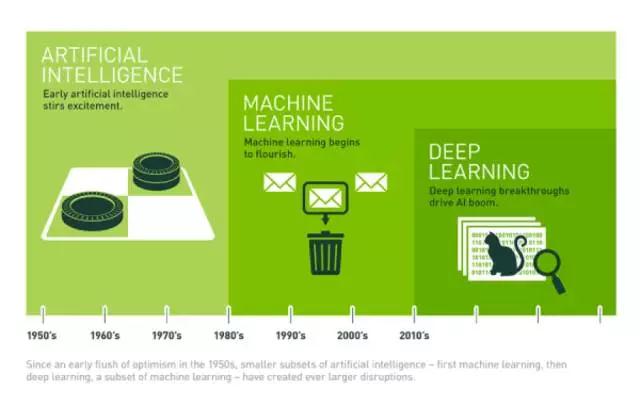
人工智能、机器学习、深度学习,这三者是什么联系?
我们能够参照下面这张图:
人工智能、机器学习、深度学习的联系
机器学习是完结人工智能的一种办法,机器学习有许多的细分范畴,其中有一个范畴是人工神经网络,而深度学习是人工神经网络这个范畴的一个分支。
二、什么是机器学习呢?
首要我们来看一下人类的学习,人类的学习是一个人根据自己的经历,对一类问题构成认知或许总结出某些规则,然后用这些认知和规则来处理相似问题的进程。
但人的回忆很简略忘掉,而且一切的常识要从头开端学,这是硬伤。但机器没有这个问题,复制粘贴立刻就有了两份常识,而且除非硬盘损坏,不然不会丢掉。
所以我们就期望,如果机器也能从常识里发现规则,并能自己学习,那就太好了。
经过核算机科学家的不断尽力,总算成功地发明晰一些算法,使得核算机能够从现有的数据中学习到规则,而且能够跟着输入的数据数量添加而提高学习作用,这就是机器学习。
网上有一张图,很有意思,生动的表明晰不同的人对机器学习的了解:
机器学习是什么
做机器学习,大部分作业其实是编程。浅显地讲:机器学习是一种核算机程序,能够从现有的经历中学习怎样完结某项使命,而且跟着经历的添加,功能也随之提高。
因而,经历,也就是专业人士说的“数据”,关于机器学习来说,就是最重要的。
就像火箭要起飞需求燃料,人要变得有才智需求履历一样,机器学习需求海量的数据。
AlphaGo 打败李世石不是由于它聪明,而是由于它经过自己和自己下棋的办法,现已相当于下了一万年以上的棋,和一个只下了几十年的人比,天然是有着不行比较的优势,它打败李世石依托的是无可比较的经历。
三、机器学习有哪些分类?
机器学习的规模很广,首要分为三大类:监督学习( Supervised Learning )、非监督学习( UnsupervisedLearning )和强化学习( Reinforcement Learning )。
监督学习:监督学习学的是带规范答案的样本。拿猫和狗的辨认来举比方。
算法看一张图就通知它,这是猫;再看一张图片,通知它这也是猫,再看一张图,通知它这是狗,如此往复。
当它看了几十万张猫和狗的图片后,你再给它一张生疏的猫或许狗的图片,就基本能“认”出来,这是哪一种。
这样的学习办法很有可能形成模型把一切答案都记了下来,但碰到新的标题又不会了的状况,这种状况叫做“过拟合”。
非监督学习:非监督学习学的是没有规范答案的样本。相同拿猫和狗的辨认举例。算法要自己去寻觅这些图片的不同特征,然后把这些图片分为两类。
它实际上不知道这两类是什么,但它知道这两类各有什么特征,当再呈现契合这些特征的图片时它能辨认出来,这是第一类图片,那是第二类图片。
强化学习:强化学习的学习办法是经过不断做出决议计划并取得成果反应后,学会主动进行决议计划,得到最优成果。
我们小时分,看到马戏团的山公竟然会做算术题,感觉到很惊奇,这是怎样做到的呢?
其实就是每次拿对了数字的时分,练习人员就给它一些食物作为奖赏,这些奖赏让他“知道”,这么做是“对的”,如果拿错了,可能就会有赏罚,这些赏罚就是要让它“知道”,这样做是“错的”。
如此一来,经过不断的练习,山公就“会”做算术题了。
四、机器学习有哪些常见算法呢?
这儿我们对常见的机器学习算法进行简略的介绍,不求精准,只求简略了解。
1. 决议计划树
决议计划树是一种用于对数据进行分类的树形结构。比方我们要买一件衣服,如果喜爱则进入下一步,看价格,如果价格适宜,就看是否有适宜的尺码,有适宜的尺码,就下单购买。用决议计划树表明如下图:
买衣服的决议计划树
2. 线性回归
试想,在纸上有许多的点,我们计划画一条直线,让这些点到这条直线的间隔之和最短,怎样找到这条直线呢?
这个办法就是线性回归。画一条线,让样本以及后边猜测的点都尽量在这条线邻近。
3. 支撑向量机和核函数
支撑向量机是一种分类办法,力求在样本中划出一道线,让线间隔两头样本的间隔最大。
它在文本分类、图画分类有较多使用。如果桌子上有红豆和绿豆,我们能够把SVM幻想成一个忍者,他画了一条线,把红豆和绿豆区别开来。
支撑向量机(SVM )
但有的时分豆子掺和在了一同,怎样办呢?我们能够针对红豆和绿豆的不同特性,把这些豆子都经过核函数进行核算,把他们映射到高维空间中去,这样豆子天然就被分开了。
参加核函数后的SVM
4. 神经网络
神经网络也是一种分类器。它是由许多个虚拟的神经元组成的一个网络,我们能够把一个神经元看做是一个分类器,那许多个神经元组成的网络就能对样本进行许屡次分类。
仍是拿忍者和豆子区别举比方。一个神经元,相当于忍者能够齐截刀,多个神经元就能够划多刀,划的越多,天然分的越细。
这儿仅仅做简略的介绍,我们有概念即可,更具体的在后边会更新。
神经网络
5. 朴素贝叶斯分类器
贝叶斯是一个定理,它的意思是:当你不能精确知悉一个事物的实质时,你能够依托与事物特定实质相关的事情呈现的多少去判别其实质特点的概率。
比方说,我们要辨认一封邮件是不是垃圾邮件。我们随机挑选出100封垃圾邮件,剖析它的特征,我们发现“廉价”这个词呈现的频率很高,100封垃圾邮件里,有40封呈现了这个词。
那我们就以这个认知为根据,得出结论:如果呈现了“廉价”,那这封邮件有40%的概率是垃圾邮件。
当我们找到若干个这样的特征,然后用这些特征进行组合后,能够对某些邮件进行判别,它是垃圾邮件的概率超越了我们设定的阈值,我们就主动把这些邮件过滤掉,削减用户遭到的打扰。这就是大部分垃圾邮件过滤的原理。
6. 聚类
聚类是一种非监督学习的办法。简略的说,就是经过不断的迭代核算,把数据分红若干个组,使得这个组里的都是相似的数据,而不同组之间的数据是不相似的。
聚类
7. 强化学习
在没有给出任何答案的状况下,先进行一些测验,经过测验所得到的报答,来断定这个测验是否正确,由这一系列的测验来不断调整和优化算法,最终算法知道在某种状况下,采纳何种动作能够得到最好的成果。
他的实质是处理“决议计划问题”,就是经过不断做出决议计划并取得成果反应后,学会主动进行决议计划,得到最优成果。比方上面说过的山公“学会”做算术题的进程。
8. 集成学习
我们在做机器学习的时分,期望能做出各个方面体现都比较好的模型。
但常常现实是我们的模型是有偏好的,可能只对某一些状况作用比较好,这个时分我们就期望把若干个这样的模型组合起来,得到一个更好更全面的模型,这种办法,就叫做集成学习。
作为一个AI入门课程,我们不需求评论过多的数学模型、算法等内容,你只需大致了解人工智能在机器学习范畴采纳的这些办法,就满足你在茶余酒后震动你的小伙伴了。
而当你具有了必定人工智能范畴的根底常识今后,你会发现淘宝摄影辨认产品,网易云音乐的听歌识曲等功能也就没有那么奥秘了。