谷歌 TensorFlow 稳居第一:23 个深度学习库的排名
来源:原创 时间:2017-11-08 浏览:0 次【导读】:根据 Github 和 Stack Overflow 上的活泼度以及 Google 查找成果,The Data Incubator 最近制作了一个 23 个抢手深度学习库的排名。
下表显现了规范化后的分数,其中值 1 表明高于均匀值的一个规范误差(均匀值为 0)。 例如,Caffe 在 Github 中的活动是一个高于均匀水准的规范差,而 deeplearning4j 挨近均匀水平。见结尾的办法。
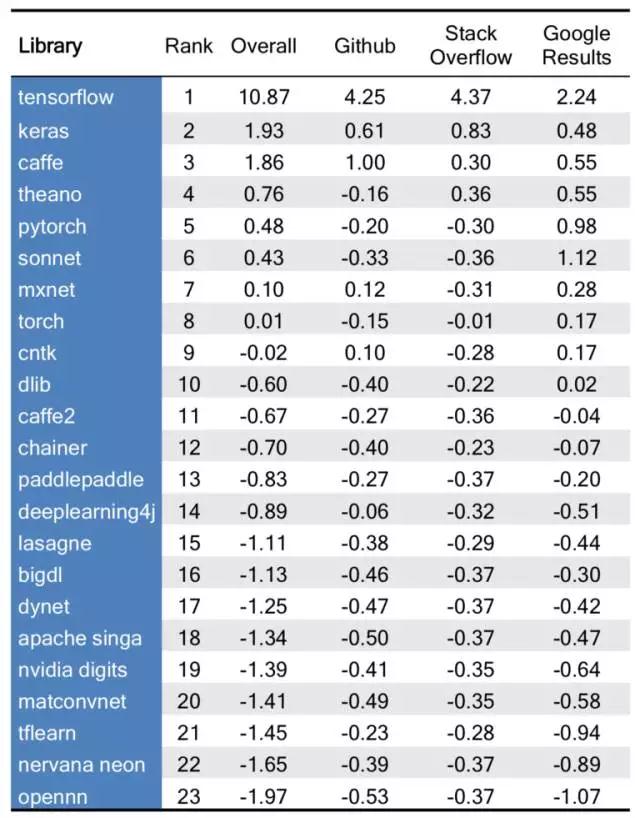
成果和评论
该排名根据三个平等重要的部分:Github(star 和 fork),Stack Overflow(标签和问题)和 Google 查找成果(总和以及季度增加率)。这 3 部分是经过可用的 API 取得的。想弄一个全面的深化学习东西包列表不容易,所以在最终选取了我们以为具有代表性的五个不同的列表(有关详细信息,请参阅下面的办法)。核算每种衡量的规范化分数,使我们能够看到在每个类别中哪些包是锋芒毕露的。
TensorFlow 在最大活泼社区中占主导
TensorFlow 在一切核算衡量上的均匀值上至罕见两个规范误差。TensorFlow 和第二大盛行结构 Caffe 比较,在 Github 上的 fork 数几乎是后者的三倍,在 Stack Overflow 上的问题总量是后者的六倍以上。TensorFlow 由 Google Brain 团队于 2015 年首度敞开,现已超过了许多的高档库,如 Theano(4)和 Torch(8),成为我们榜单的首位。TensorFlow 尽管与在 C++ 引擎上运转的 Python API 一同分发,但表中的几个库能够将 TensorFlow 用作后端,并供给它们自己的接口。这些库包含了 Keras(2),将很快成为 TensorFlow 和 Sonnet 的中心部分(6)。TensorFlow 的盛行可能是其通用的深度学习结构,灵敏的界面,美观的核算图形可视化和 Google 的重要开发人员和社区资源的合力下的成果。
Caffe 尚未被 Caffe2 所替代
Caffe 在我们的名单上排名第三,除了 TensorFlow 外,Caffe 其在 Github 上的活泼度比其他竞争对手都要多。Caffe 传统上被以为比 Tensorflow 更专业,而且专心于图画处理,方针辨认和预先练习的卷积神经网络。Facebook 于 2017 年 4 月发布了 Caffe2(11),而且现已排在了深化学习库的上半部分。Caffe2 是一个更轻盈、模块化和可扩展的 Caffe 版别,包含循环神经网络。Caffe 和 Caffe2 是彼此独立的库房(repo),所以数据科学家能够持续运用开始的 Caffe。可是,有一些搬迁东西,比方如 Caffe Translator,它供给了一种运用 Caffe2 来驱动现有 Caffe 模型的办法。
Keras 是深度学习上最受欢迎的前端库
Keras(2)是排名最高的非结构库。Keras 能够用作 TensorFlow(1)、Theano(4)、MXNet(7)、CNTK(9)、deeplearning4j(14)的前端。在一切的三个衡量规范上, Keras 的体现均优于均匀水平。Keras 的盛行可能是因为其简单性和易用性。Keras 答应快速的原型化,但价值是献身了从结构直接运转而发生的一些灵敏性和操控。数据科学家在数据集上做深度学习的相关试验时,Keras 遭到了他们的喜爱。跟着 R Studio 最近发布了 Keras 的界面,Keras 的开展和受欢迎程度还在不断连续。
即便没有巨子支撑,Theano 仍坚持独占鳌头
在新的深度学习结构的海洋中,Theano(4)是我们的排名中最陈旧的库。Theano 创始性地运用了核算图(computational graph),并在研讨界遍及做深度学习和机器学习之时仍坚持盛行。Theano 本质上是一个 Python 的数值核算库,但能够与像 Lasagne 这样的高档深度学习库(15)一同运用。尽管 Google 支撑 TensorFlow(1)和 Keras(2),Facebook 支撑 PyTorch(5)和 Caffe2(11),MXNet(7)是 Amazon Web Services 的官方深度学习结构,Microsoft 规划并保护了 CNTK(9),Theano 在没遭到职业巨子的正式支撑下仍然盛行。
Sonnet 是增加最快的库
2017 年头,Google 的 DeepMind 揭露发布了 Sonnet(6)的代码,这是一个以 TensorFlow 为根底的高档面向对象库。Sonnet 的 Google 查找成果回来页数比上个季度增加了 272%,是我们列表中一切库中最大的。尽管 Google 在 2014 年收买了英国人工智能公司DeepMind,但 DeepMind 和 Google Brain 仍然在大体上是独立团队。DeepMind 专心于通用人工智能,Sonnet 能够协助用户为他们的详细 AI 主意和研讨做顶层规划。
Python 是深度学习的接口言语
PyTorch(5)是我们表中增加速度第二的库,该结构的仅有接口是 Python。与上季度比较,PyTorch 的 Google 查找成果增加了 236%。在我们排的 23 个开源深度学习结构和包装器中,只要三个没有 Python 接口:Dlib(10)、MatConvNet(20)和OpenNN(23)。在 23 个库中,C ++ 和 R 接口别离只要 7 个和 6 个。尽管数据科学界在运用 Python 方面有些挨近同一个一致,但对深度学习库而言,还有许多的挑选。
约束
当然,有些库因为现已存在了更长的时刻会有更高的数据,因而排名更高。仅有考虑到这一点的目标,是 Google 查找季度增加率。
数据出现中遇到的一些困难:
·神经规划和 wolfram 数学是专有的,故被删去
·cntk 也被称为「微软认知东西包」,可是我们只运用了 ctnk 称号
·neon 变成了 nervana neon
·paddle 被改为 paddlepaddle
·一些库显然是其他库的衍生品,如 Caffe 和 Caffe2。如果它们有独自/独立的 Github 库房,我们分隔处理这些库。
办法
一切源代码和数据都在我们的 Github 页面上。我们首先从五个不同的来历中生成了 23 个开源深度学习库的列表,然后收集了一切这些库的目标,以取得排名。
Github 的数据根据 star 数和 fork 数、Stack Overflow 的数据包含包称号的标签和问题,Google 查找成果则根据曩昔五年的 Google 查找成果总数,并核算成果在曩昔三个月与前三个月比较的季度增加率。
一些注意事项:
·有几个库是常用词汇(caffe、chainer、lasagne),因而用于断定 Google 查找成果数量的查找词,包含库的称号和术语即“deep learning”。
·任何不可用的 Stack Overflow 计数都转换为零计数。
·计数被规范化为均值 0 和误差 1,然后均匀得到 Github 和 Stack Overflow 分数,并结合 Serch 成果,然后得到总分。
·做了一些手动查看以承认 Github 库房方位。